1 min read
Create a Data Platform in Just 30 Days!
Have you ever thought about creating a data platform in Azure but gotten overwhelmed with the process? Or maybe you can think back to previous failed...
4 min read

Data Science is an intensely broad field, requiring a vast array of skills and presenting some pervasive patterns of challenges. In this blog, I will discuss some of these patterns of pervasive challenges based upon my experience, and map to three solutions within the Azure environment: Azure Databricks, Azure ML, and Azure Synapse Analytics.
If you follow the Data Science field, you are probably aware of the evolution of Venn diagrams that strive to capture the essence of skillset required of a Data Scientist. I have my favorites (yes, plural), and they tend to fluctuate over time, based upon my latest emphasis or revelation of a new twist. Most of the diagrams differentiate the core skills of a Data Scientist from those of a Data Analyst, Machine Learning Engineer among others, as a way of defining the landscape.
No Venn diagrams are included here; perhaps this is a topic for another day. Ultimately, this theoretical topology of the field probably matters very little to you. What matters more is the range of things that you need to accomplish in your world, and what you need in terms of skills, tools, and experience in order to do what is needed. This is scoped by the practical constraints inherent in working within the established teams and processes in the context of your environment (e.g., organization, company).
In my Data Science leadership experience spanning multiple industries - advertising technology, medical devices, and drone flight analysis to name a few - there are a handful of recurring patterns of key challenges. Cast in terms of the Data Science lifecycle, these cluster in toward the beginning and end of the lifecycle. At the core of the Data Science lifecycle is Machine Learning, a highly iterative experimental process.
The following sections dive into each pattern of Data Science challenge, and for each, discuss specific solutions within Azure (Azure Databricks, Azure ML, and Azure Synapse Analytics) that are particularly appropriate in framing a solution.
Establishment and management of the data platform is the normal realm of the Data Engineering function, closely aligned with Data Science. While the precise boundary is variable, Data Engineering tends to manage the actual data via common data access services (e.g., APIs), whereas Data Science gravitates toward the more specialized fluid requirements for data transformation. Particularly in certain industries (e.g., medical devices), there are strict governance and security controls on the data platform, spanning from requirements to validation, thus placing challenges on accessing the underlying data.
Azure Databricks provides support for both Data Engineering and Data Science, built upon Spark as the basis of a productive, collaborative platform and code-first data pipelines. Databricks and Synapse both provide access to Azure Data Factory and other Azure tools for data platform development.
The Azure ML capabilities for developing data pipelines have significant overlap with developing models, described in the next section.
Azure Synapse Analytics provides high performance data warehousing for low-latency, high-concurrency BI as well as analytics, integrated with no-code / low-code development. Given their breadth of capabilities, Databricks and Synapse are often viewed as a choice (somewhat dependent on the code-first versus low-code difference, as well as the degree of emphasis on data warehousing); they are also sometimes used in tandem. Both play well with Azure ML.
The development of data pipelines and ML models is core to the Data Science lifecycle. Very often, Data Science groups are charged with devising a “proof-of-concept” (PoC) that establishes viability of a proposed approach, while providing a tangible object of demonstration. In these situations, it is often desirable to leverage high-level APIs and tools – for example, tools for visually specifying and assembling pipelines. It is also important to have a clear path toward more custom code model development efforts (i.e., “getting under the hood”) as the need arises.
Azure Databricks has ML-optimized runtimes which include leading ML frameworks (e.g., TensorFlow, PyTorch, Keras).
Azure ML provides a variety of model development capabilities. Via Designer, it supports low-code and no-code approaches to visually establishing a data pipeline by specifying transformations, exploring datasets, and training/testing models. Via Python SDK, Data Scientists can also tie in python notebooks. Azure ML also provides access to Automated ML, which is often very useful in establishing an initial baseline of “best performing model” against which more extensive efforts can be gauged. In the aggregate, these services provide a relatively seamless path from rapid establishment of a PoC and model baseline to deeper more advanced development of models including custom ML algorithms.
While Azure Synapse Analytics is based on providing services for BI (including Power BI visualizations), it also ties in Azure ML services through the Linked Services capability.
All three of these Azure solutions support the pervasive Data Science use of the notebooks paradigm, and the architectural selection process goes beyond consideration of data science requirements.
Machine Learning Operations (MLOps) is based on DevOps principles and practices that include continuous integration, delivery, and deployment. MLOps applies these principles to the machine learning process, aimed at greater efficiency and quality throughout the workflow including experimentation, development, and deployment of models to Production.
Azure Databricks supports MLOps through a variety of services related to Spark clusters; specifically model deployment is managed through the use of MLflow.
Azure ML supports MLOps with a wide variety of services, including creation of reproducible ML pipelines, reusable software environments, and the ability to deploy end-to-end workflow components (including pipeline and predictive services) in an automated manner. In addition, it provides a capability called Data Drift, which facilitates setting up dataset monitors on Machine Learning to track how data “in the wild” is changing over time and assess against the model for evolving performance.
Azure Synapse Analytics has a native integration with Azure Machine Learning and Azure Cognitive Services. As a high-level AI API, the latter is another component of Azure that enables high value for data science in the spirit of low-code.
The data science lifecycle exhibits patterns of recurring challenges: establishing data pipelines, developing ML models, and deploying these pipelines and models. These challenges are addressed by a combination of solutions within Azure that include Azure Databricks, Azure ML, and Azure Synapse Analytics. Beyond the specifics of these specific areas, the holistic architectural solution emerges from strong integration among these Azure technologies as depicted in the following architecture diagram-
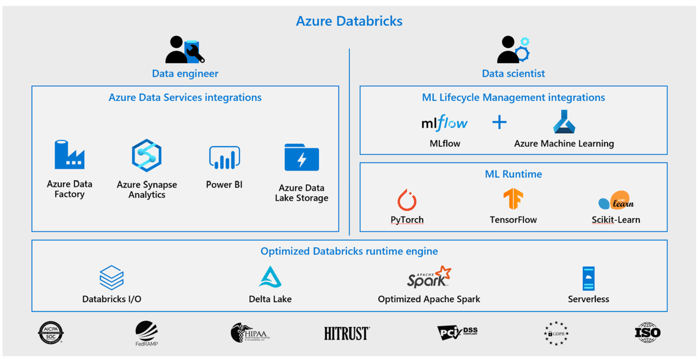
Want to learn more about Azure in the context of Data Science? Contact us today, we are happy to discuss!

1 min read
Have you ever thought about creating a data platform in Azure but gotten overwhelmed with the process? Or maybe you can think back to previous failed...

1 min read
Round 1: The Managed Database... FIGHT! The world of database management and application development has changed. We’ve seen a swift and long-time...
.png)
1 min read
In the rapidly evolving landscape of Generative AI (GenAI), managing costs effectively is crucial for businesses leveraging Azure's cloud...