1 min read
Get The Most Out of Microsoft Power Platform With The COE Starter Kit
Center of Excellence (COE) Starter Kit – Advantages, Do’s, and Don’ts and, Troubleshooting
1 min read

Delta Format is a popular format for data lake storage. It is usually faster than other formats, like CSV or parquet. Delta Format can be optimized further by using partitioning.
In a Synapse Data Flow in the Delta Sink properties, under Optimize tab, there is an option to set partitions based on some columns.
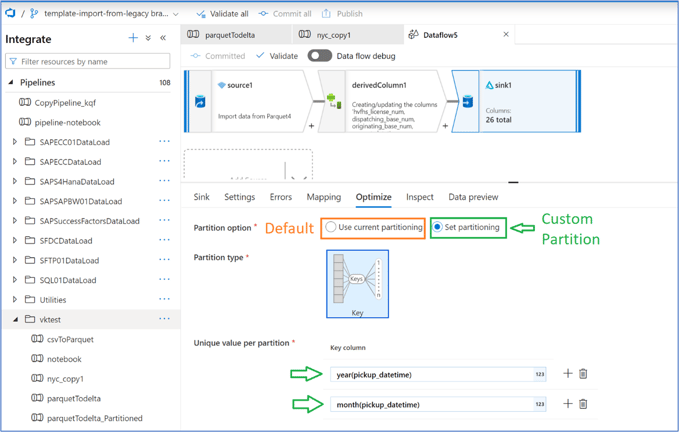
We can also use expressions to build the columns to partition on. In the screenshot above, we have taken the year portion and the month portion of the DateTime type column.
The result of this setting is that when data is stored in the destination delta lake, it is partitioned by the columns specified.
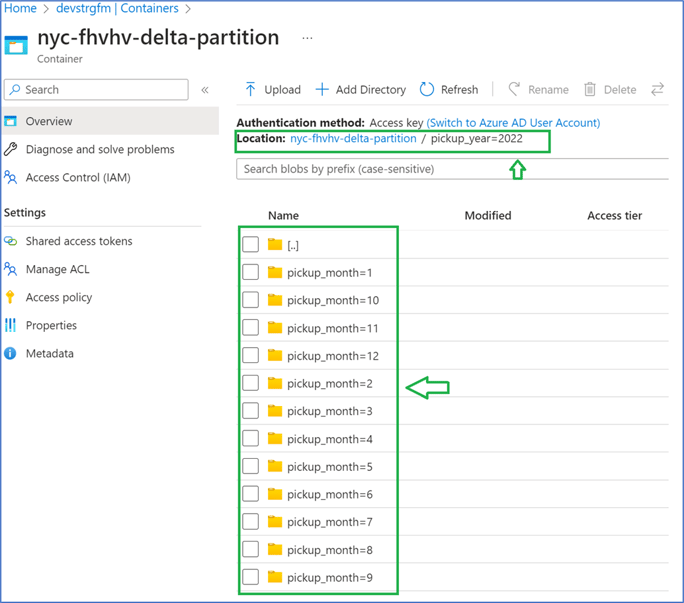
Now, consider the effect of partitioning on query performance on POC test that we ran.
Total rows:
Two Hundred Twelve Million
212,416,083
The query to find total rows is as follows:


5:27:14 PM
Started executing query at Line 1
Statement ID: {AD969CB9-C053-466C-98E3-2AD067F52900} | Query hash: 0x8B798F62DD481716 | Distributed request ID: {7CA770A2-7B52-4B55-9831-66F0D8A62BCC}. Total size of data scanned is 122 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.
(2 records affected)
Total execution time: 00:00:04.038

The improvement will be more pronounced once the data volume increases further.
Now for comparison, if you also look at parquet and put expressions in predicate statements, it takes a lot longer to execute. In this case, 600% longer.
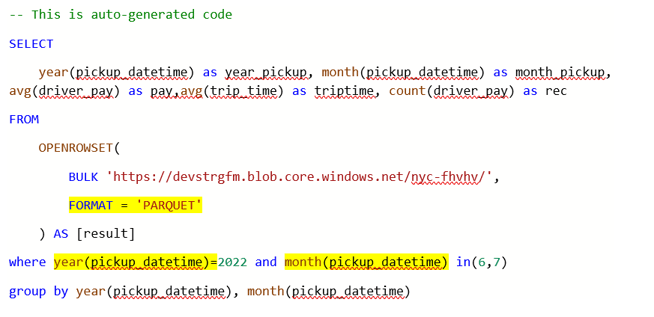
5:45:08 PM
Started executing query at Line 1
Statement ID: {AB0F9CE9-38D5-4DCA-8BA9-0856B9A76613} | Query hash: 0x8A11904118881710 | Distributed request ID: {4F1DEE7E-5C76-4897-A2EC-8B2DDB64C931}. Total size of data scanned is 2088 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.
(2 records affected)
Total execution time: 00:00:24.042
The aforementioned findings highlight the potential for enhancing query efficiency by strategically organizing vast volumes of data into logical groups. By capitalizing on smaller data subsets, queries can be optimized for improved performance.
Furthermore, the experiment emphasizes the inefficiency of incorporating expressions within predicates, specifically within the WHERE clause. It is advisable to steer clear of this practice to prevent compromising query performance. If you have any questions on this topic or want to discuss further, please contact us today!

1 min read
Center of Excellence (COE) Starter Kit – Advantages, Do’s, and Don’ts and, Troubleshooting
.png)
1 min read
In the world of large-scale data and analytics projects, achieving seamless integration between infrastructure, development, and data engineering...

1 min read
Spyglass recently helped a large higher education institution create a solution for managing Microsoft O365 Service Health, Message Center, and...