 William Richard
William Richard
.png)

1 min read
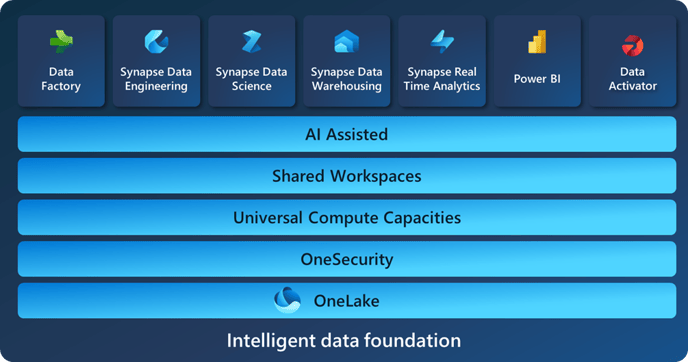
Accelerating Data Ingestion with Microsoft Fabric: A Lakehouse-Based Framework Using Pipelines, PySpark, and Medallion Architecture
In today’s data-driven landscape, organizations are under pressure to ingest, transform, and analyze external data sources rapidly and reliably. As...
.png)
.png)